
Python(4):组合数据类型-序列/列表/元组/字典/集合
序列和索引
序列(Sequence)
- 序列,是一个用于存储多个值的连续空间。
- 属于列表结构的还有列表、元组、字典和集合。其中,列表和元组称为有序序列,字典和集合称为无序序列。此四类又合称为Python中的组合数据类型。
索引(Index)
- 序列中的每一个值都对应一个整数的编号,称为索引。
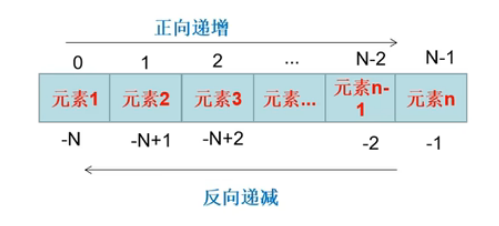
索引有两种类型:正向递增索引和反向递减索引。
如下图:
- n个元素组成序列的正向递增索引的范围是从0(对应第一个元素)到n-1(对应第n个元素);
- n个元素组成序列的反向递减索引的范围是从-n(对应第一个元素)到-1(对应第n个元素)。
例5.1:使用索引检索字符串中的元素
说明
正向递增
假设字符串
s是'helloworld',len(s)是 10。range(len(s))生成从 0 到 9 的整数序列。第一次循环:
i是 0s[i]是s[0],即'h'print(i, s[i], end='\t\t')打印0 h,然后添加两个制表符\t\t
第二次循环:
i是 1s[i]是s[1],即'e'print(i, s[i], end='\t\t')打印1 e,然后添加两个制表符\t\t
- 依次类推,直到
i为 9。
- 反向递减:同理如上。
# 正向递增
s='helloworld'
for i in range(0, len(s)):
print(i,s[i],end='\t\t')
print('\n---------------')
# 反向递减
for i in range(-10,0):
print(i,s[i],end='\t\t')
# 正反一致性
print('\n',s[9],s[-1]) # 其获取的字符是一致的序列的操作
序列的切片(Slicing)
- 参见:索引和切片
- 切片是访问序列中一定范围内元素的一种方法,不仅可以应用于字符串,还有其他类型。
切片操作的语法结构:
[start:end:step]start: 切片的开始索引(包含)end: 切片的结束索引(不包含)step: 步长(默认为1)1- 例:序列 [0:5:2]
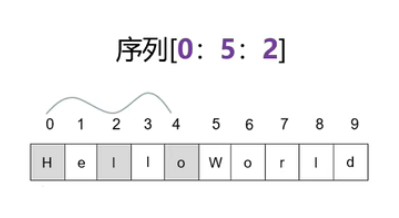
例5.2:序列的切片操作
s='Helloworld'
# 切片操作
s1=s[0:5:2] # 索引从0开始,到5结束(不含5),步长为2,结果为:Hlo
print(s1)
# 省略开始位置,start默认从0开始
print(s[:5:1]) # 结果为:Hello,等同于print(s[0:5:1])
# 省略开始位置和步长,start默认从0开始,step默认为1
print(s[:5:]) # 结果为:Hello,等同于print(s[0:5:1])
# 省略结束位置,stop默认到序列的最后一个元素(包含最后一个)
print(s[0::1]) # 结果为:Helloworld,等同于print(s[0:11:1])
# 省略结尾位置和步长
print(s[5::]) # 结果为:world
print(s[5:]) # 同上
# 省略开始位置和结束位置,只写步长
print(s[::2]) # 会获取索引为0/2/4/6/8的元素,结果为:Hlool
# 步长为负数
print(s[::-1]) # 逆向输出,结果为:dlrowolleH
print(s[-1:-11:]) # 使用反向递减索引,结果同上序列的函数和操作符
| 操作符/函数 | 描述说明 |
|---|---|
| x in s | 若x是s的元素→True;反之False |
| x not in s | 若x非s的元素→True;反之False |
| len(s) | 序列s元素的个数(即:序列的长度) |
| max(s) | 序列s元素的最大值 |
| min(s) | 序列s元素的最小值 |
| s.index(x) | 检索x首次出现在序列s中的位置 |
| s.count(x) | 检索x出现在序列s中的次数 |
例5.3:序列相加和相乘
s='Hello'
s2='World'
print(s+s2) # 产生一个新的字符串序列
# 序列的相乘操作
print(s*5) # 重复五次,代替循环
例5.4:序列的相关操作符和函数的使用
s='helloworld'
# x in s 的使用
print('e在s中存在吗?',('e' in s))
print('v在s中存在吗?',('v' in s))
# x not in s 的使用
print('e在s中不存在吗?',('e' not in s))
print('v在s中不存在吗?',('v' not in s))
# 内置函数
print('len():',len(s))
print('max():',max(s))
print('min():',min(s))
# 序列对象的方法(使用序列的名称,打点调用)
print('s.index():',s.index('o')) # 输出o首次出现的索引值
print('s.index():',s.index('v')) # v不存在,会报错ValueError
print('s.count():',s.count('o'))组合数据类型1:列表(List)
定义
- 列表是指一系列的、按照特定顺序排列的元素组成,与int/float/str这类不可变字符序列都不尽相同。
- 是Python中内置的可变序列。
- 在Python中使用[]定义列表,元素与元素之间使用英文的逗号分隔。
- 列表中的元素可以是任意的数据类型。
创建与删除列表
使用[]直接创建列表
语法结构:name=[element1,element2,......,elementN]
使用内置函数list()创建列表
语法结构:name=list(序列)
删除
语法结构:del name
例5.5:列表的创建与删除
# 直接使用[]创建列表
l=['hello','world',98,3.14,'100'] # 列表中可包含不同数据类型
print(l)
# 使用内置函数list()
l2=list('helloworld')
l3=list(range(1,10,2)) # 从1开始到10结束,不包含10,步长2
print(l2)
print(l3)
# 列表是序列的一种,对序列的操作符、运算符、函数均适用
print(l+l2+l3) # 列表相加
print(l*3) # 列表相乘
print(len(l))
print(max(l))
print(min(l))
print(l2.count('o'))
print(l2.index('o'))
# 列表的删除
l4=[10,20,30]
print(l4)
del l4
print(l4) # 删除后出现NameError错误,证明删除有效遍历列表:enumerate函数
语法结构
enumerate 函数在 Python 中是一个非常有用的工具,它允许你在遍历一个可迭代对象(如列表、元组或字符串)时,同时获取元素的索引和值。这在很多情况下都非常有用,因为它可以让你的代码更简洁和易读。
语法结构:enumerate(iterable, start=0)
例5.6:三种列表的遍历操作
# 直接使用for循环
l1=['Hello','world','python','php']
for i in l1:
print(i,end='\t\t')
print(end='\n')
# 输出结果为Hello world python php
# 使用for+range+len
for i in range(0,len(l1)):
print(i,'--->',l1[i],end='\t\t')
print(end='\n')
# 输出结果为0 ---> Hello 1 ---> world 2 ---> python 3 ---> php
# 使用enumerate
for a,b in enumerate(l1):
print(a,b,end='\t\t')
# 输出结果为0 Hello 1 world 2 python 3 php
# 使用enumerate时可以手动修改序号的起始值
for a,b in enumerate(l1,start=1): # 代表从列表l1的第二个元素开始
print(a,b)
for a,b in enumerate(l1,1): # start可以省略不写,等效如上
print(a,b)
列表的方法
| 方法 | 描述说明 |
|---|---|
| s.append(x) | 在列表s最后增加一个元素x |
| s.insert(n,x) | 在列表序列n处增加一个元素x |
| s.clear() | 清除列表s中的所有元素 |
| s.pop(n) | 将列表s中序列n处位置元素取出,并从列表中删除 |
| s.remove(x) | 将列表s中出现的第一个元素x删除 |
| s.reverse(x) | 将列表s中的元素x反转
注意,print(s.reverse()) 无返回值,只会返回None |
| s.copy() | 拷贝列表s中的所有元素,生成一个新列表 |
| s[x]= | 修改列表s中序列为x的元素 |
例5.7:列表的相关操作
lst=['hello','world','python']
print('原列表:',lst,id(lst))
# 增加元素
lst.append('spl')
print('增加元素之后:',lst,id(lst))
# 之所以列表被称为可变数据类型,就是因为其元素可变的同时,内存地址保持不变
# 插入元素
lst.insert(_index:1,_object:100)
print(lst)
# 在索引1(第二个位置)位置插入100,其他元素后撤1
# 删除元素
lst.remove('world')
print(lst,id(lst))
# 使用了删除后,内存位置依然不会变
# 先取出再删除
print(lst.pop(1)) # 会先将100取出,再删除
print(lst)
# 清空元素
lst.clear()
print(lst,id(lst)
# 逆向输出
lst2=['hello','world','python']
lst2.reverse() # 不会产生新列表,在原列表的基础上进行
print(lst2)
# 列表拷贝,将产生一个新列表
lst3=lst2.copy()
print(lst2,id(lst2)) # 内存位置依然不会变
print(lst3,id(ist3))
# 列表元素修改
lst2[1]='mysql'
print(lst2)列表的排序
sort方法
语法结构:s.sort(key=None,reverse=False)
key表示排序的规则,reverse表示排序方式,默认升序。
内置函数sorted()
语法结构:sorted(iterable,key=None,reverse=False)
iterable表示可迭代的排序对象,其他同上。
例5.8:列表的排序操作(sort方法)
lst=[4,56,3,78,40,56,89]
print('原列表:',lst)
# sort方法升序:整数
lst.sort() # 排序是在原列表的基础上进行的,不会产生新的列表对象
print('升序:',lst)
# sort方法降序:整数
lst.sort(reverse:True)
print('降序:',lst)
print('-'*20)
lst2=['banana','apple','Cat','Orange']
print('原列表:',lst2)
# sort方法升序:英文字母
lst2.sort() # 先排大写,再排小写。因为按照ASCII码值,大写+32=小写
print('升序:',lst2)
# sort方法降序:英文字母
lst2.sort(reverse:True)
print('降序:',lst2)
# 自制定规则:忽略大小写
lst2.sort(key=str.lower) # 参数,不加括号(只有调用加括号)
print(lst2)例5.9:列表的排序操作(sorted函数)
lst=[4,56,3,78,40,56,89]
print('原列表:',lst)
# sorted升序:整数
asc_lst=sorted(lst) # 使用sorted排序需要先定义一个新的列表对象
print('升序:',asc_lst)
print('原列表:',lst)
# sorted降序:整数
desc_lst=sorted(lst,reverse=True)
print('降序:',desc_lst)
print('原列表:',lst)
print('-'*20)
lst2=['banana','apple','Cat','Orange']
print('原列表:',lst2)
# sorted忽略大小写排序
lst3=sorted(lst2,key=str.lower) # 参数,不加括号(只有调用加括号)
print('原列表:',lst2)
print('sorted列表:',lst3)
列表生成式(List Comprehension)
语法结构
s=[expression for item in range]
s=[expression for item in range if condition]
例5.10:列表生成式的使用
import random
lst=[x for x in range(1,11)]
print(lst) # 将生成1-10的整数
lst=[x*x for x in range(1,11)]
print(lst) # 将生成1-10每个数的平方数
lst=[random.randint(1,100) for _ in range(10)]
print(lst) # 将产生10个1-99之间的随机数
# 从列表中选择符合条件的元素组成新的列表
lst=[for i in range(10) if 1%2==0]
print(lst) # 筛选偶数例5.11:二维列表的遍历与列表生成式
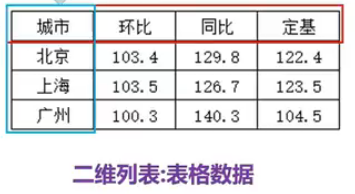
# 创建二维列表
lst=[
['城市','环比','同比','定基']
['北京',103.4,129.8,122.4]
['上海',103.5,126.7,123.5]
['广州',100.3,140.3,104.5]
]
print(lst)
# 遍历二维列表,使用双层for循环
for row in lst: # 行
for item in row: # 列
print(item,end='\t')
print() # 换行
# 列表生成式:生成一个4行5列的二维列表
lst2=[ [j for j in range(5)]for i in range(4)]
print(lst2)组合数据类型2:元组(Tuple)
定义
- 是Python中内置的不可变序列。
- 在Python中使用()定义列表,元素与元素之间使用英文的逗号分隔。
- 元组中只有一个元素时,逗号也不能省略。
创建与删除元组
元组的创建
使用()直接创建
语法结构:name=(element1,element2,...,elementN)
使用内置函数tuple()创建元组
语法结构:name=tuple(index)
元组的删除
语法结构:del name
例5.12:元组的创建与删除/元组作为序列的基本属性
# 使用小括号直接创建
t=('hello',[10,20,30],'python','world')
print(t)
# 使用内置函数tuple()创建
t=tuple('helloworld')
print(t) # 会自动把字符串的每一个字母拆分成单个元素输出
t=tuple([10,20,30,40])
print(t) # 会自动把列表中的每一个整数拆分成单个元素输出
# 序列操作:判断
print('10在元组中是否存在',(10 in t))
print('10在元组中不存在',(10 not in t))
# 序列操作:最值
print('maximum',max(t))
print('minimum',min(t))
# 序列操作:长度
print('length',len(t))
# 序列操作:查找和计数
print('index',t.index(10))
print('count',t.count(10))
# 单元素元组逗号不可省略
x=(10)
print(type(x)) # 整数类型,而非元组
y=(10,) # 单元数元组的逗号不可省略
print(type(y))
# 删除元组
del y
# print(y)就会报错遍历/访问元组
例5.13:切片/访问,通过三种方式遍历元组
t=('python','hello','world')
# 根据索引访问元组
print(t[0])
# 切片
t2=[0:3:2]
print(t2)
# for遍历
for i in t:
print(i)
# for+range()+len()遍历
for j in range(len(t)):
print(i,t[i])
# enumerate遍历
for k,l in enumerate(t,start=1): # 序号从1开始,不是序列从1开始
print(k,'-->',l)
元组生成式(Tuple comprehension)
例5.14:元组生成式/__next__()方法取出元组元素
t=(for i in range(1,4))
print(t) # 输出生成器对象(迭代器)本身,而不是其中的元素
t=tuple(t)
print(t) # 输出为了元组元素
# __next__方法
# __next__方法无法只能遍历迭代器/生成器,不能遍历元组本身
u=(for j in range(1,4))
print(u.__next__()) # 取第一个(序列0)元素
print(u.__next__()) # 取第二个(序列1)元素
print(u.__next__()) # 取第三个(序列2)元素
print(u.__next__()) # 取第四个(序列3)元素
u=tuple(u) # 现在元组已经空掉了元组和列表的区别
| 元组 Tuple | 列表 List |
|---|---|
| 不可变序列 | 可变序列 |
| 不能添加、删除和修改元素等操作 | 可通过append(), insert(), remove(), pop()等方法添加、删除列表元素 |
| 支持索引访问、切片,不支持修改 | 支持索引访问、切片、修改元素 |
| 访问和处理速度快 | 访问和处理速度慢 |
| 可作为字典的键 | 不可作为字典的键 |
组合数据类型3:字典(Dictionary)
定义
字典类型是根据一个信息查找另一个信息的方式构成了“键值对(key-value pair)”,它表示索引用的键(key)和对应的值(value)构成的成对关系。
- 与列表类似,字典也是Python中的可变数据类型。
- 与列表不一样的是,字典中的元素是无序的,这基于其排列元素时底层使用的哈希函数。但字典中可以通过键来查找元素。
- 键在字典中是唯一的,不允许重复;但值可以出现重复。
- 字典中的键要求是不可变序列:整数、浮点、字符串和元组均可,但列表不可。
创建与删除字典
字典的创建
使用{}直接创建
语法结构:name={key1:value1,key2:value2...}
使用内置函数dict()创建字典
语法结构:name=dict(key1=value1,key2=value2...)
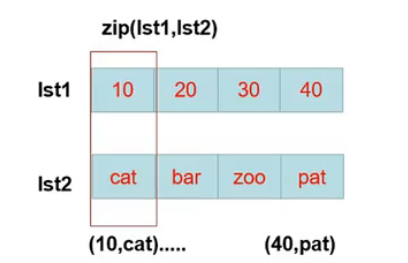
使用映射函数zip()创建字典
语法结构:zip(lst1,lst2)
前置序列(列表或元组均可)对应key,后置序列对应value。zip()函数会自动对应相同索引的元素为一对。
字典的删除
语法结构:del name
例5.15:字典的创建与删除
# 使用{}创建
d={10:'cat',20:'dog',30:'pet',20:'zoo'}
print(d)
# 出现两个相同key时,不会报错,后者value会覆盖前者value,保证key唯一
# zip()创建对象的性质:哈希值-->以元组形式为元素的列表
lst1=[100,200,300,400]
lst2=['a','s','d','f','g']
zipa=zip(lst1,lst2)
print(zipa) # 输出一个hash值(zip object at hash_value),代表一个zip对象
print(list(zipa)) # 使用list()创建zipa为列表对象,发现列表中的元素为元组类型
# 第五个value不对应任何key,因此被略过
# 此时dict已经被转为了list
# 使用zip()创建字典
lst3=[100,200,300,400]
lst4=['a','s','d','f','g']
zipb=zip(lst3,lst4)
d2=dict(zipb)
print(d2)
# 使用参数创建字典
d=dict(cat=10,dog=20) # cat is key, 10 is value
print(d)
# 元组可以作为键,因为元组不可变
t=(10,20,30)
print({t:10}) # t is key, 10 is value
# 列表不能作为键,因为列表可变
# lst=[10,20,30]
# print({lst:10})
# TypeError: unhashable type: 'list'
# 字典的序列性质:最值、长度(元素个数)
print('maximum:',max(d))
print('minimum:',min(d))
print('length(number of elements):',len(d))
# 字典的删除
del d
# print(d)
# NameError: name 'd' is not defined.字典元素的取值和遍历
取值
字典没有整数索引,反之,其使用键来实现取值。
语法结构:①d[key] ;或②d.get(key)
区别:若键不存在,①会报错,②会指定默认值。
遍历
遍历出key与value的元组
for element in d.items():
pass
分别遍历出key和value
for key.value in d.items():
pass
例5.16:字典元素的访问和遍历
# 创建字典
d={'hello':10,'world':20,'python':30}
# 访问元素:d(key)
print(d['hello'])
# 输出为10
# 访问元素:d.get(key)
print(d.get('hello')
# 输出为10
# 两种访问的区别
# print(d['java'])
# KeyError: 'java'
print(d.get('java'))
# 不会报错,默认输出None
print(d.get('java','不存在'))
# 会输出指定值“不存在”代替None
# 字典遍历
for i in d.items():
print(i) # 得到key=value的元组类型
for key,value in d.items():
print(key,'---->',value)
字典的方法
| 方法 | 描述说明 |
|---|---|
| d.keys() | 获取所有key数据 |
| d.values() | 获取所有value数据 |
| d.pop(key,default) | key存在,获取相应value,同时删除该键值对; key不存在,获取默认值 |
| d.popitem() | 随机取出一对键值对,结果为元组类型,同时从字典中删除该键值对 注:Python 3.7版本后,该指令效果为“删除并返回‘最后插入’的键值对” |
| d.clear | 清空字典中的所有键值对 |
例5.17:字典的相关操作
d={1001:'abc',1002:'def',1003:'ghi'}
print(d)
# 添加元素
d[1004]='jkl'
print(d)
# 获取keys
keys=d.keys()
print(keys)
print(list(keys))
print(tuple(keys))
# 获取values
values=d.values()
print(list(values))
print(tuple(values))
# 转为键值对元组列表
lst=list(d.items())
print(lst)
# 转回字典
d=dict(lst)
print(d)
# 使用pop删除键值对
print(d.pop(1001))
print(d)
print(d.pop(1008,'not exist'))
# 使用popitem删除末尾键值对
print(d.popitem())
print(d)
# 清空字典元素
d.clear()
print(d)
# Python中一切皆对象,每个对象都有一个布尔值
print(bool(d)) # 空字典布尔值为False
# 空列表、空元组的布尔值亦为False字典生成式(Dictionaty comprehension)
① d={key:value for item in range}
② d={key:value for key,value in zip(lst1,lst2)}
例5.18:字典生成式
import random
d={for item:random.randint(1,100) in range(4)}
print(d)
lst=[1001,1002,1003]
lst2=['a1','b2','c3']
d-{key:value for key,value in zip(lst,lst2)}
print(d)组合数据类型4:集合(Set)
定义
- Python中的集合与数学中集合的概念一致。
- 它是一个无序的、不重复的元素序列。
- 集合中只能存储不可变数据类型。
- 集合使用{}定义。
- 集合自身属于可变类型。
创建与删除集合
集合的创建
使用{}直接创建
语法结构:name={element1,element2,...}
使用内置函数set()创建字典
语法结构:name=set(iterable)
集合的删除
语法结构:del name
例5.19:集合的创建与删除
# 使用{}创建
s={10,20,3.14}
# s={[10,20],[3.14]} TypeError: unhashable type: 'list'
print(s)
s={}
print(s,type(s)) # 一对空花括号会创建一个空字典,而非空集
# 使用set()创建集合
s=set() # 创建了一个空集
print(s)
print(bool(d)) # 空集的布尔值为False
s=set('helloworld')
print(s) # 输出结果会随机打乱元素排序,且只保留重复元素中的一个
s2=set([10,20,3.14]) # set()函数支持使用列表的不可变元素创建集合
s3=set(range(1,10))
print(s2)
print(s3)
# 集合的序列性质:最值、长度(元素个数)、判断存在
print('maximum:',max(s3))
print('minimum:',min(s3))
print('length(number of elements):',len(s3))
print('9 exist in set or not:',(9 in s3))
print('9 not exist in set:',(9 not in s3))
# 集合的删除
del s3
# print(s3)
# NameError: name 's3' is not defined.集合操作符
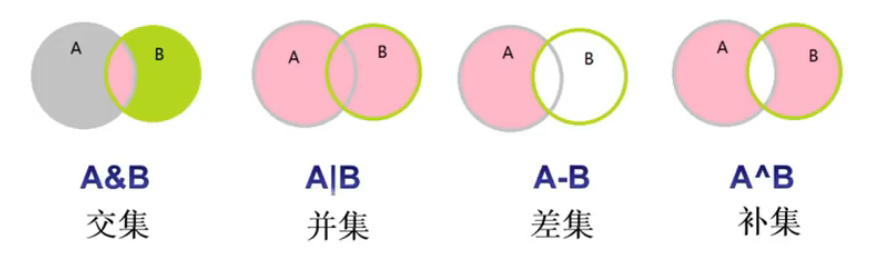
- 交集:
A&B→ A∩B - 并集:
A|B→ A∪B - 补集:
A^B→ $(A \cap B)^\complement \cap (A \cup B)$ - 差集:
A-B→ $A-A(A \cap B)$
例5.20:集合操作符
A={10,20,30,40,50}
B={30,50,76,88,20}
# 交集
print(A&B)
# 并集
print(A|B)
# 差集:A减去相交部分
print(A-B)
# 补集:AB并集减去相交部分
print(A^B)集合的操作方法、遍历和生成式
| 方法 | 描述说明 |
|---|---|
| s.add(x) | 若x不在s中,则添加x到集合s |
| s.remove(x) | 若x在s中,将其删除;若不在,程序报错 |
| s.clear() | 清空集合中的所有元素 |
例5.21:集合的操作方法/遍历/生成式
s={10,20,30}
# 添加元素
s.add(100)
print(s)
# 删除元素
s.remove(20)
print(s)
# 清空元素
s.clear()
print(s)
# 遍历:for
s={10,30,100}
for i in s:
print(i)
# 遍历:enumerate
for index,i in enumerate(s):
print(index,'-->',i)
# 集合生成式
s={i for i in range(1,10)}
print(s)
s={for i in range(1,10) if i%2==1}
print(s)Python 3.11新特性
结构模式匹配
语法结构
match data:
case {}:
pass
case []:
pass
case ():
pass
case _:
pass
例5.22:结构的模式匹配
data=eval(input('Type in your data to match:'))
match data:
case {'name':'njsukleo','pw':123456}:
print('dict')
case (10,20,30):
print('tuple')
case ([10,20,30]):
print('list')
case _:
print('NOT MATCHED') #equal to the else in multiple if
字典合并运算符
例5.23:合并字典的运算符|
d1={'a':10,'b':20}
d2={'c':30,'d':40,'e':50}
merged_dict=d1|d2
print(merged_dict)
# 输出合并后的字典,结果应该是 {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50}。同步迭代
语法结构
match data1,data2:
case data1,data2:
pass
例5.24:同步迭代
fruits=['apple','orange','pomegranate','avocado']
counts=[10,3,4,5]
for f,c in zip(fruits,counts):
match f,c:
case 'apple',10:
print('10 apples')
case 'orange',3:
print('3 oranges')
case 'pomegranate',4:
print('4 pomegranates')
case 'avocado',5:
print('5 avocados')
- 即:每隔“步长-1”字符访问一次 ↩
