
Python(5): 模块及常用的第三方模块
1 模块(Module)
1.1 模块的定义、功能和特点
- 在Python中,一个后缀名为 $.py$的Python文件就是一个模块。
- 模块中可以定义函数、类等,是特定功能代码的一种封装。
- 模块也可以避免函数、类、变量等名称相冲突的问题。
- 模块不仅提高了代码的可维护性,还提高了代码的可复用性。
- 模块的命名规范如下:①全部使用小写字母;②多个单词之间使用下划线分隔。
- 若自定义模块名称与系统内置模块名称相同,在导入时会优先导入自定义模块。
1.2 模块的分类
1.2.1 系统内置模块
有开发人员编写好的模块,在安装Python解释器时一同安装至计算机。
1.2.2 自定义模块
一个以 $.py$结尾的文件就是一个自定义模块。
1.2.2.1 作用
- 规范代码,将功能相同的函数、类封装到一个模块中,提高代码可读性。
- 可被其他模块调用,提高开发效率。
1.2.2.2 例10.1:自定义模块my\_info
# 假设本模块名为“my_info.py”
# 自定义变量
name='njsukleo'
# 自定义函数
def info():
print(f'Hello, everyone. I am {name}')
1.2.3 第三方模块
由全球Python爱好者、程序员、各行各业的专家进行开发和维护。
1.2.3.1 安装与卸载(以下指令适用于cmd/Powershell)
安装:pip install module_name
卸载:pip uninstall module_name
升级pip:python -m pip install —upgrade pip
检测是否安装了某个第三方库:pip show module_name
1.3 模块的导入
1.3.1 import导入
- 语法结构:
import module_name [as alias] - 若模块名过长,允许在import后定义一个别名(alias)进行简便调用。
- 注意,在取别名后,打点调用时必须使用别名。
1.3.2 from...import导入
- 语法结构:
from module_name import variant/function/class/* - 通过此方式可以导入模块中的变量、函数和类。$*$是通配符,表示导入全部内容。
1.3.3 例10.2-10.4:模块的导入
import my_info
print(my_info.name) # 打印自定义模块的变量
my_info.info() # 执行自定义模块的函数
import my_info as a # 定义别名
print(a.name)
a.info()
from my_info import name
print(name) # 此种方式不需要再打点调用
# info()使用不了,因为没有导入(NameError)
from my_info import info
info()
from my_info import * # 导入全部内容
print(name)
info()
# 同时导入多个模块
import math,time,random
# 调用时有同名变量或函数冲突:后者会覆盖前者
# 解决方法:使用import ...导入模块后单个打点调用变量或函数
# 假设有一个intro.py模块中与my_info.py有同名变量和函数
from my_info import *
from intro import *
info() # 此时会调用intro模块中的info函数
import my_info
import intro
my_info.info()
intro.info()
# 确保了两个函数不发生冲突2 包(Package)
2.1 定义
包(package)是含有 $\verb|__init__.py|
$文件的文件夹(目录)。
可以避免模块名称相冲突的问题。
2.2 创建包
在PyCharm中右击目录,选择$\verb|New >> Python Package|
$,再进行命名即可。
包创建完成后,自带一个空的 $\verb|__init__.py|
$文件。
2.3 包的导入
2.3.1 import导入
导入语法结构:import package_name.module_name [as alias]
2.3.2 from...import导入
以“包名-模块名”导入的语法结构:from package_name import module_name [as alias] (打点调用)
以“包名.模块名-函数名/变量名”导入的语法结构:from package_name.module_name import variant/function_name [as alias] (无需打点调用)
2.3.3 init执行问题
不论使用哪种方法导入包,其中的$\verb|__init__.py|
$文件都会自动导入并执行。
这种执行只会在包初次被导入时发生且仅发生一次。
2.4 主程序运行(重要)
if __name__ == '__main__' :
pass
2.4.1 例10.5:使用主程序运行阻止全局变量的输出执行
假设有以下模块$\verb|module_a.py|
$:
# module_a.py
print('welcome to Beijing')
name='njsukleo'
print(name)
同目录下,有$\verb|module_b.py|
$代码如下:
# module_b.py
import module_a此时执行$\verb|module_b.py|
$,上一模块中的指令会被执行。若我们不想在导入模块的同时执行它们而只是导入,我们可以使用主程序运行避免其执行。
我们修改$\verb|module_a.py|
$内容如下:
# module_a.py
if __name__ == '__main__' :
print('welcome to Beijing')
name='njsukleo'
print(name)
此时再执行$\verb|module_b.py|
$,导入模块的两句代码不再被执行。
3 常用系统内置模块/Python标准库
在安装Python解释器时一并安装进来的模块(大约270个)称为系统内置模块,也被称为标准模块或标准库。
标准库位置:$\verb|.../Python/Python3.11/Lib|
$
| 标准库名称 | 说明 |
|---|---|
| os | 与操作系统和文件相关操作有关 |
| re | 在字符串中执行正则表达式 |
| random | 产生随机数 |
| json | 对高维数据进行编码和解码 |
| time | 与时间相关 |
| datetime | 与日期时间相关,可以方便地显示和运算日期 |
3.1 random模块
random模块是Python中用于产生随机数的标准库。
| 函数名称 | 说明 |
|---|---|
| seed(x) | 初始化给定的随机数种子,默认为当前系统时间戳 |
| random() | 产生一个[0.0,1.0)之间的随机浮点数 |
| randint(a,b) | 产生一个[a,b]之间的随机整数 |
| randrange(m,n,k) | 产生一个[m,n)之间步长为k的随机整数 |
| uniform(a,b) | 产生一个[a,b]之间的随机浮点数 |
| choice(seq) | 从序列seq中随机选择一个元素 |
| shuffle(seq) | 打乱序列seq并返回打乱后的新序列 |
3.1.1 例10.11:random模块的使用
import random
# 设置种子
random.seed(10)
print(random.random())
print(random.random()) # [0,1), float
# 因为随机种子固定,重复运行此两行,所得随机数相同
# 按住Ctrl点选random,可从标准库文档中查看所调用的函数
print('-'*20)
random.seed(10)
print(random.randint(1,100)) # [1,100], integer
for i in range(10): # 取10次随机数
print(random.randrange(1,10,3)) # [1,10), integer, step=3
print(random.uniform(1,100)) # [1,100], float
lst=[for i in range(1,11)]
print(random.choice(lst)) # 随机从lst取一个元素
random.shuffle(lst)
print(lst)
random.shuffle(lst)
print(lst) # 两次结果不一样
3.2 time模块
3.2.1 函数
| 函数名称 | 说明 | ||
|---|---|---|---|
| time() | 获取当前时间戳 | ||
| localtime(sec) | 获取指定时间戳对应的本地时间的$\verb | struct_time | |
| $对象 | |||
| ctime() | 获取当前时间戳对应的易读字符串 | ||
| strftime() | 格式化时间,结果为字符串 str→string; ft→format | ||
| strptime() | 提取字符串的时间,结果为$\verb | struct_time | |
| $对象 | |||
| sleep(sec) | 休眠$\verb | sec | $秒 |
3.2.2 格式化字符串(formatted string)
| 格式化字符串 | 说明 | 取值范围 | ||
|---|---|---|---|---|
| $\verb | %Y | $ | 年份 | 0001-9999 |
| $\verb | %m | $ | 月份 | 01-12 |
| $\verb | %B | $ | 月名 | January-December |
| $\verb | %d | $ | 日期 | 01-31 |
| $\verb | %A | $ | 星期 | Monday-Sunday |
| $\verb | %H | $ | 小时(24h制) | 00-23 |
| $\verb | %I | $ | 小时(12h制) | 01-12 |
| $\verb | %M | $ | 分钟 | 00-59 |
| $\verb | %S | $ | 秒 | 00-59 |
3.2.3 例10.12:time模块的使用
import time
now=time.time()
print(now) # 输出时间戳
obj=time.localtime()
print(obj) # 输出struct_time对象
obj2=time.localtime(60)
print(type(obj2),obj2) # 时间戳为60时,输出为1970/1/1 GMT+8 8:01
print('Year:',obj2.tm_year)
print('Month:',obj2.tm_mon)
print('Date:',obj2.tm_mday)
print('Hour:',obj2.tm_hour)
print('Min:',obj2.tm_min)
print('Second:',obj2.tm_sec)
print('Weekday:',obj2.tm_wday) # 取值[0,6],因此2表示星期三
print('Day of the year:',obj2.tm_yday) # 今年第几天
print(time.ctime()) # ctime-->易读字符串
# 日期时间格式化
print(time.strftime('%Y-%m-%d',time.localtime()))
print(time.strftime('%H:%M:%S',time.localtime()))
print(time.strftime('%B',time.localtime())) # 月份名称
print(time.strftime('%A',time.localtime())) # 星期名称
# 字符串转回struct_time对象
print(time.strptime('2008-08-08','%Y-%m-%d')
# 程序暂停秒数
time.sleep(20)
print('helloworld')3.3 datetime模块
| 类名 | 说明 |
|---|---|
| datetime.datetime | 表示日期时间的类 |
| datetime.timedelta | 表示时间间隔的类 注意:年、月不可计算 |
| datetime.date | 表示日期的类 |
| datetime.time | 表示时间的类 |
| datetime.tzinfo | 时区相关的类 |
| datetime子类的函数 | 说明 |
|---|---|
| datetime(y,m,d,h,m,s) | 通过传入参数创建包含从年到秒的datetime对象 |
| datetime.now() | 获取当前时间 |
| timedelta子类的函数 | 说明 |
|---|---|
| timedelta(d,sec) | 通过传入参数创建timedelta对象 |
3.3.1 例10.13:datetime类的使用
from datetime import datetime
dt=datetime.now() # 获取当前系统时间
print(dt)
# 手动创建对象
dt2=datetime(2077,1,14,16,35)
print(type(dt2),dt2) # 类型为class
print(dt2.year,dt2.month,dt2.day) # 年月日时分秒都可以取出
# 比大小
d1=datetime(2028,5,1,0,0,0)
d2=datetime(2028,10,1,0,0,0)
print('2028/5/1 earlier than 2028/10/1?',d1<d2)
# datetime class -> str
nwt=datetime.now()
print(type(nwt)) # 验证nwt为class
nwt_str=nwt.strftime('%Y/%m/%d %H:%M:%S')
print(type(nwt_str)) # 验证nwt_str为str
# datetime str -> class
str_time='2077/7/7 07:07:07'
d3=datetime.strptime(str_time,'%Y/%m/%d %H:%M:%S')
print(type(str_time),str_time) # 验证
print(type(d3),d3) # 验证d3为class和d3的数据3.3.2 例10.14:timedelta类的使用
from datetime import datetime
from datetime import timedelta
# 进行datetime类型之间的算术运算
delta1=datetime(2028,10,1)-datetime(2028,5,1)
print(type(delta1),delta1) # 153 days, 0:00:00
print('validation',datetime(2028,5,1)+delta1)
# 通过传入参数创建timedelta对象
dt1=timedelta(10)
print('a 10-day timedelta obj:',dt1) # 创建10天的timedelta对象
4 常用第三方库
4.1 requests模块(处理HTTP请求/爬虫)
4.1.1 简介
- 用于处理超文本传输协议(HTTP)请求的第三方库,该库在爬虫(web crawlers)中应用广泛。
- 使用requests库中的
get()函数可以打开一个网络请求,并获取一个$\verb|Response|$响应对象。 - 响应结果中有字符串数据也有二进制数据(如图片、音频、视频等),前者可以通过响应对象的$\verb|text|$属性获取,后者可以通过响应对象的$\verb|content|$属性获取。
4.1.2 函数
| 函数 | 说明 | ||
|---|---|---|---|
| get() | 打开一个网络请求,并获取一个$\verb | Response | $响应对象 |
4.1.3 例10.15:爬取“中国天气网”中“景点推荐”模块的天气数据
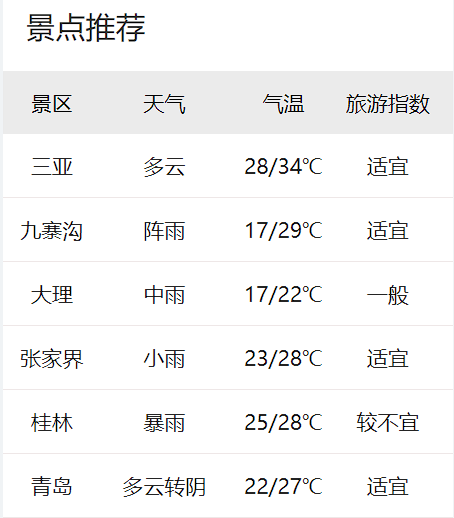
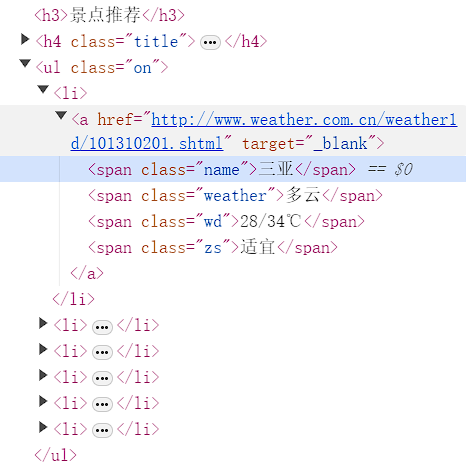
import requests
import re # 正则表达式模块
url1='http://www.weather.com.cn/weather1d/101120101.shtml'
resp_obj=requests.get(url1) # 获取一个响应对象,定义为resp_obj
resp_obj.encoding='utf-8' # 设置编码格式
print(resp_obj.text) # 对象名.属性名,可获取html语言格式的网页内容
# 进一步使用正则表达式提取对象
city=re.findall('<span class="name">([\u4e00-\u9fa5]*)</span>',resp_obj.text)
weather=re.findall('<span class="weather">([\u4e00-\u9fa5]*)</span>',resp_obj.text)
temperature=re.findall('<span class="wd">(.*)</span>',resp_obj.text)
situation=re.findall('<span class="zs">([\u4e00-\u9fa5]*)</span>',resp_obj.text)
print('二维列表')
print(city)
print(weather)
print(temperature)
print(situation)
lst=[] # 使用列表打包数据
for a,b,c,d in zip(city,weather,temperature,situation):
lst.append([a,b,c,d])
print('一维数据')
print(lst)4.1.4 例10.16:爬取百度的Logo图片
import requests
url='https://www.baidu.com/img/PCfb_5bf082d29588c07f842ccde3f97243ea.png'
r=requests.get(url)
# 保存到本地
with open('logo.png','wb')as file1: # 二进制文件,使用with()覆写
file1.write(r.content)
4.2 openpyxl模块(写入/读取Excel数据,自动化办公)
4.2.1 简介
- 用于处理Microsoft Excel文件的第三方库。
- 可以对Excel文件中的数据进行写入和读取。
4.2.2 函数
| 函数 | 说明 |
|---|---|
| load\_workbook(filename) | 打开已存在的表格,结果为工作簿对象 |
| workbook.sheetnames | 工作簿对象的sheetnames属性,用于获取所有工作表的名称,结果为列表类型 |
| sheet.append(lst) | 向工作表中(末尾)添加一行数据 |
| workbook.save(excelname) | 保存工作簿 |
| Workbook() | 创建新的工作簿对象 |
4.2.3 例10.18:把上例天气数据存储至Excel中
# weather.py
# 封装
import requests
import re # 正则表达式模块
def get_html():
url1='http://www.weather.com.cn/weather1d/101120101.shtml'
resp_obj=requests.get(url1) # 获取一个响应对象,定义为resp_obj
resp_obj.encoding='utf-8' # 设置编码格式
return resp_obj.text
def parse_html(h_str):
# 进一步使用正则表达式提取对象
city=re.findall('<span class="name">([\u4e00-\u9fa5]*)</span>',h_str)
weather=re.findall('<span class="weather">([\u4e00-\u9fa5]*)</span>',h_str)
temperature=re.findall('<span class="wd">(.*)</span>',h_str)
situation=re.findall('<span class="zs">([\u4e00-\u9fa5]*)</span>',h_str)
lst=[] # 使用列表打包数据
for a,b,c,d in zip(city,weather,temperature,situation):
lst.append([a,b,c,d])
return lst
import weather
import openpyxl
html=weather.get_html() # 发请求,得响应结果
lst=weather.parse_html(html) # 解析数据
# 创建新工作簿
workbook=openpyxl.Workbook()
# 创建工作表
sheet=workbook.create_sheet('景区天气')
# 添加数据
for item in lst:
sheet.append(item) # 循环一次添加一行
workbook.save('景区天气.xlsx')4.2.4 例10.19:从Excel中读取数据
import openpyxl
# 打开工作簿
wb=openpyxl.load_workbook('景区天气.xlsx')
# 选择要操作的工作表
sheet=wb['景区天气']
# 先遍历行,后遍历列
lst=[] # 存储行数据
for row in sheet.rows:
sublst=[] # 存储单元格数据
for cell in row:
sublst.append(cell.value)
lst.append(sublst)
for item in lst:
print(item)
4.3 pdfplumber模块(读取PDF内容,自动化办公)
4.3.1 简介
pdfplumber模块可用于从PDF文件中读取内容。
4.3.2 例10.20:从pdf提取数据
import pdfplumber
with pdfplumber.open('1.pdf') as file1:
for i in file1.pages:
print(i.extract_text()) # extract_text()方法提取内容
print(f'-------------第{i.page_number}页提取完成')
4.4 Numpy模块
4.4.1 简介
Numpy是Python数据分析方向和其他库的依赖库,用于处理数组、矩阵等数据。
Numpy也可以用来处理图片。
4.4.2 例10.21:图像的灰度处理
import numpy as np
import matplotlib as plt
# 读取图片
n1=plt.imread('google_logo.png')
# 输出为三维数组,最高维度表示图片的高度,次高维度表示宽度,最低维度是RGB
plt.imshow(n1)
# 编写一个灰度公式
n2=np.array([0.299,0.587,0.114]) # 创建数组
# n1(RGB)与n2(灰度)点乘运算
x=np.dot(n1,n2)
# 传入数组,显示灰度
plt.imshow(x,cmap='gray')
# 显示图像
plt.show()4.5 Pandas模块和Matplotlib模块
4.5.1 简介
- Pandas是基于Numpy模块扩展的一个非常重要的数据分析模块,使用Pandas读取Excel数据更加方便。
- Matplotlib是用于数据可视化的模块,使用$\verb|Matplotlib.pyplot|$可以便捷绘制饼图、柱形图、折线图等。
4.5.2 例10.22:绘制饼图
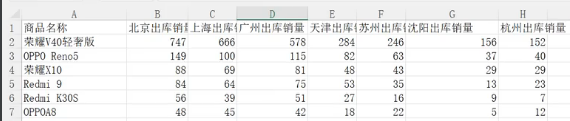
import pandas as pd
import matplotlib.pyplot as plt
# 读取Excel文件
df = pd.read_excel('JD销售数据.xlsx')
# 解决中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置画布大小
plt.figure(figsize=(10, 6))
# 提取数据
labels = df['商品名称']
y = df['北京出库销量']
# 绘制饼图
plt.pie(y, labels=labels, autopct='%1.1f%%', startangle=90)
# 设置x/y轴刻度
plt.axis('equal')
# 设置标题
plt.title('JD销量(北京)各品牌占比')
# 显示图表
plt.show()
4.6 PIL/pillow模块(模糊图像)
4.6.1 简介
用于图像处理的第三方库,它支持图像存储、处理和显示等操作。
# 安装时,模块名字为“pillow”
pip install pillow# 调用时,模块名字为“PIL”
from PIL import Image4.7 jieba模块(中文分词)
4.7.1 简介
用于对中文进行分词。
